
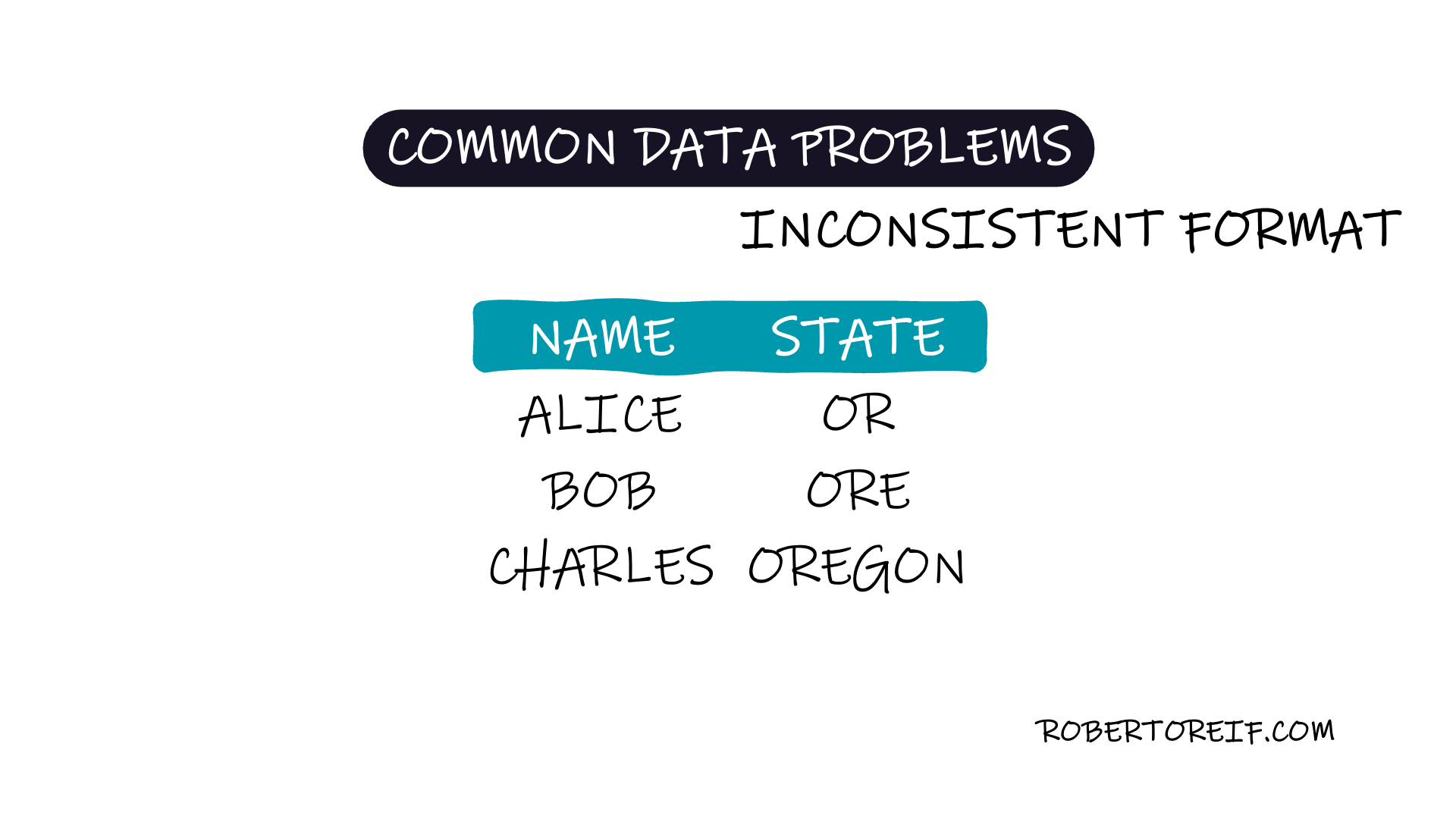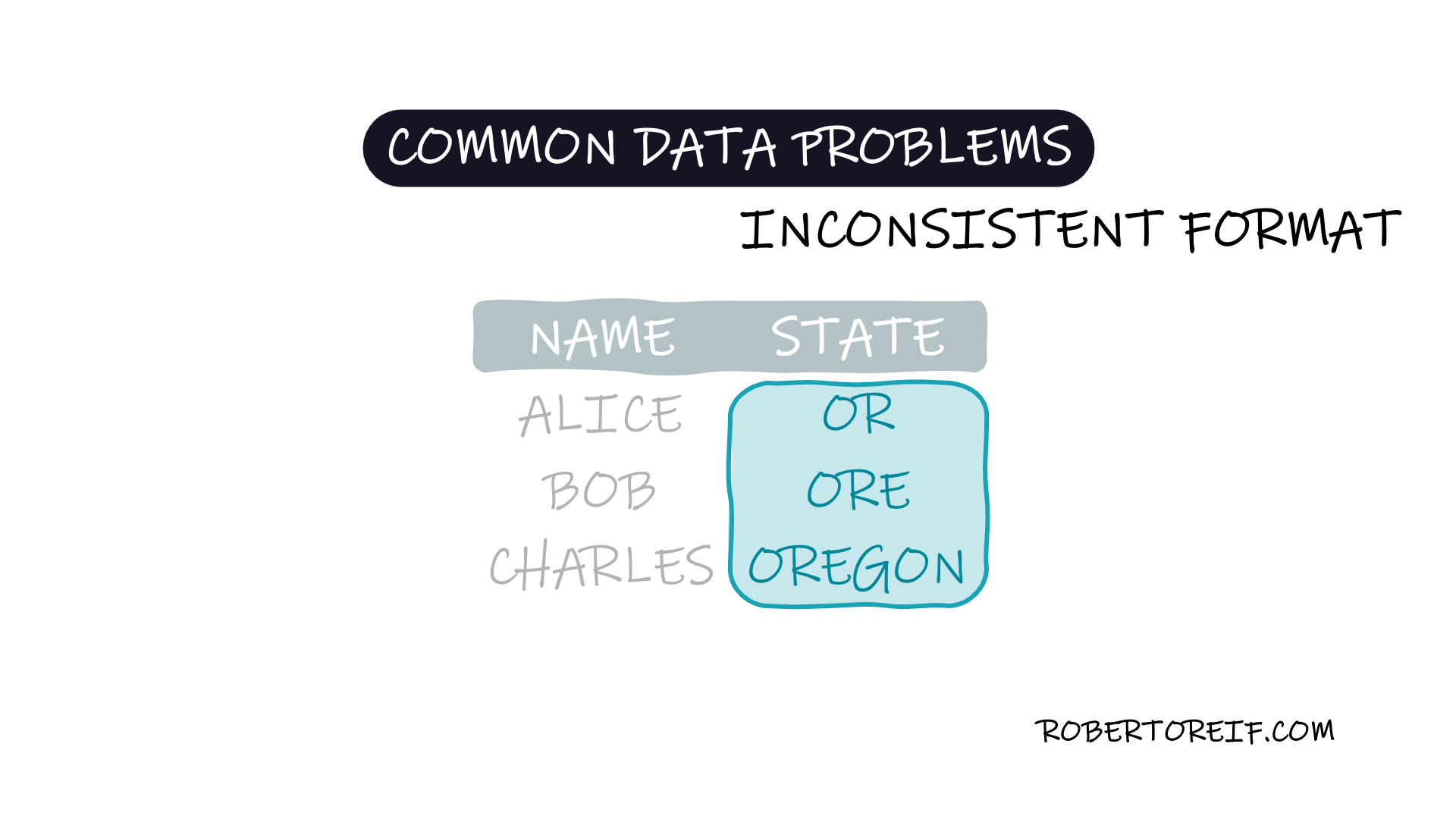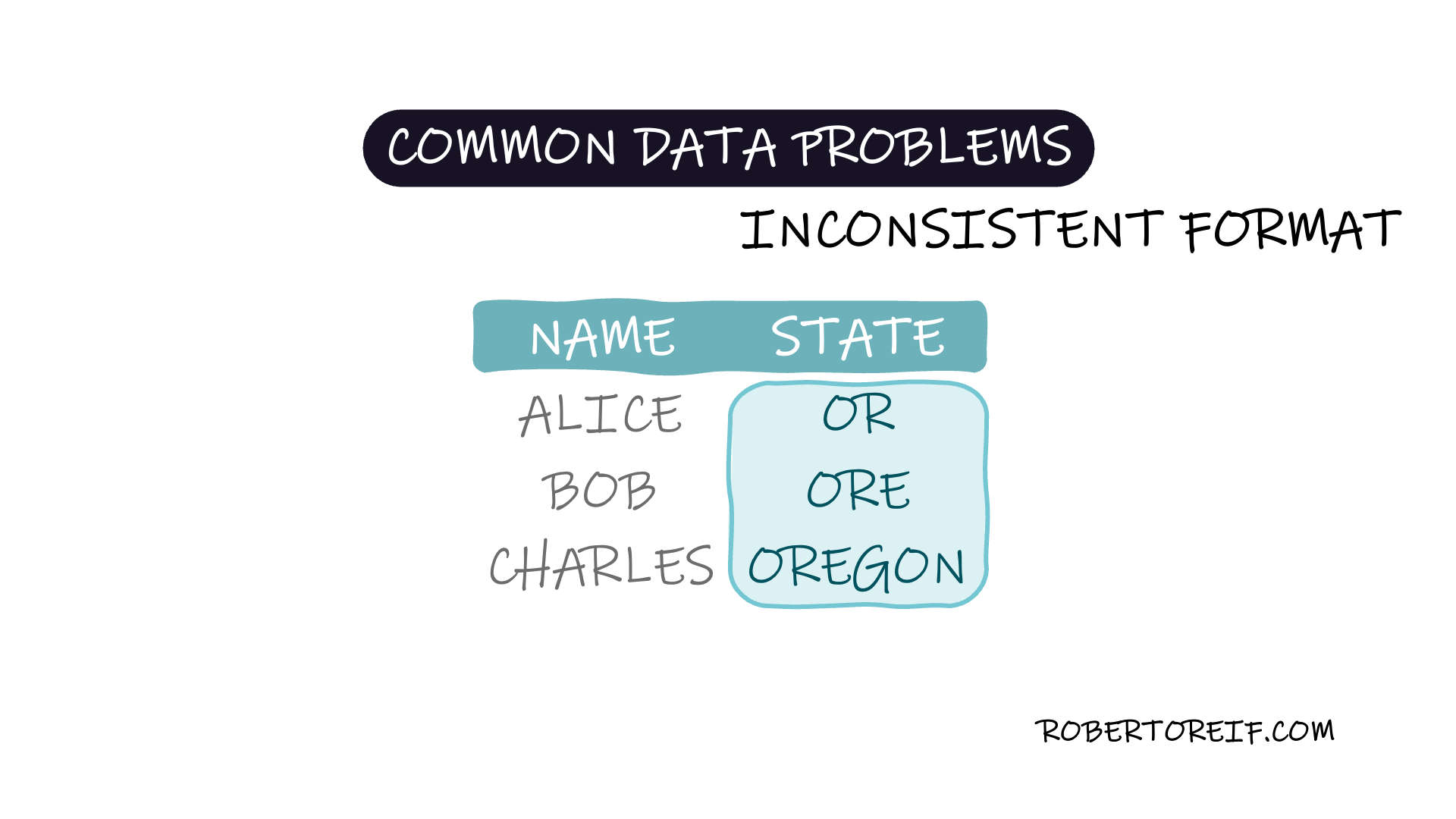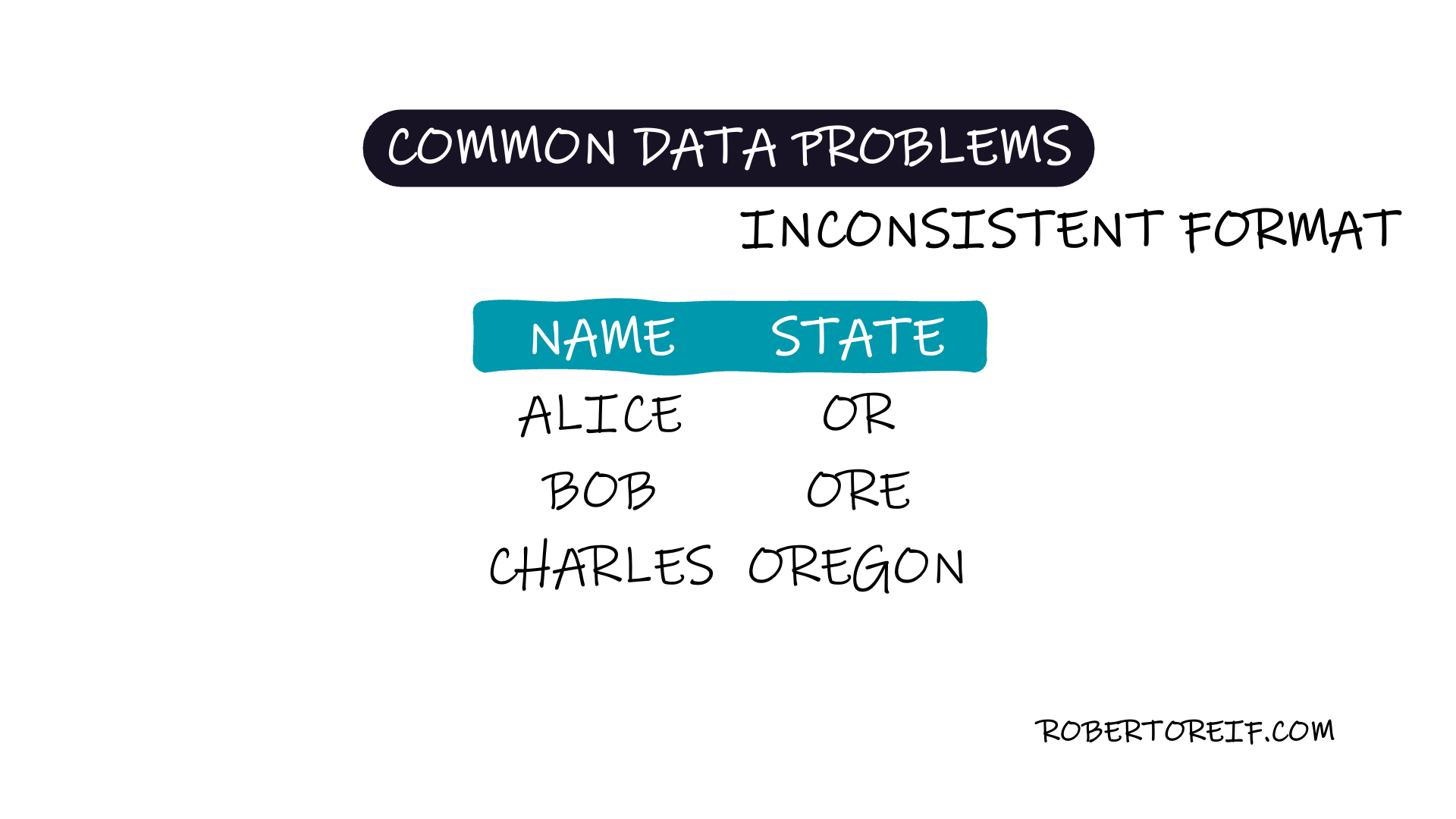
One of the most frequent problems when working with datasets is inconsistent data formatting. These inconsistencies arise when the same information is recorded in multiple formats, making it harder to analyze, group, or draw meaningful insights from the data.
Inconsistent data format can look like:
State names recorded as both "CA" and "California"
Different capitalization: "seattle", "Seattle", "SEATTLE"
Date formats like "01/06/2024", "2024-06-01", or "June 1, 2024"
Duplicates due to spelling differences: "McDonalds" vs. "McDonald's"
These variations are typically the result of manual data entry, lack of standardized input rules, or integrating data from multiple sources.
In order to handle inconsistent data we can implement:
Standardization using dictionaries or mapping rules: create a reference dictionary to convert all variants into a unified, canonical format (e.g., always convert "California" to "CA").
Consistent casing: convert text to a uniform case (e.g., all lowercase or title case) to reduce variation caused by capitalization.
Data validation during entry: use dropdown menus, input masks, or regular expressions to restrict how data can be entered at the source.
Use controlled vocabularies and schemas: especially when integrating from multiple sources, agree on a predefined schema or standard to ensure uniformity.
Inconsistent data can cause serious issues during grouping, filtering, or merging operations, and even lead to misleading results in analysis.
What techniques have worked best for you when handling inconsistent data?